Jerikan+Ansible : un système de gestion de configuration pour le réseau
ex-Blade Network Team
23 minutes de lecture
Aussi disponible en
Classé dans
Document lié :
Il existe de nombreuses ressources pour l’automatisation du réseau avec Ansible. La plupart d’entre elles n’exposent que les premières étapes ou se limitent à un champ d’application réduit. Elles donnent peu d’indications sur la manière d’aller plus loin. Les environnements réseau réels peuvent être vastes, polyvalents, hétérogènes et remplis d’exceptions. L’absence d’exemples concrets de déploiements Ansible, contrairement à Puppet et SaltStack, conduit de nombreuses équipes à élaborer des solutions fragiles et incomplètes.
Nous avons publié sous une licence libre notre tentative pour pallier ce manque :
- Jerikan, un outil pour construire des fichiers de configuration à partir d’une source de vérité unique et de modèles Jinja2, ainsi que son intégration dans GitLab ;
- un playbook Ansible pour déployer ces fichiers de configuration sur les équipements réseau ;
- les données de configuration et les modèles pour nos centres de données, aujourd’hui fermés, à San Francisco et en Corée du Sud, couvrant de nombreux fournisseurs (Facebook Wedge 100, Dell S4048 et S6010, Juniper QFX 5110, Juniper QFX 10002, Cisco ASR 9001, Cisco Catalyst 2960, serveurs de console Opengear et serveurs Linux) et de nombreuses fonctionnalités (approvisionnement, routage BGP vers l’hôte, routage Internet, réseau d’administration séparé, configuration DNS, intégration avec NetBox et les IRR).
Voici une démo pour l’ajout d’un nouveau peering:
Ce travail est l’œuvre collective de Cédric Hascoët, Jean-Christophe Legatte, Loïc Pailhas, Sébastien Hurtel, Tchadel Icard et Vincent Bernat. Nous sommes l’équipe réseau de Blade, une société française exploitant Shadow, un produit de PC dans les nuages. En mai 2021, notre société a été rachetée par Octave Klaba et l’infrastructure est en cours de transfert vers OVHcloud, sauvant ainsi Shadow en tant que produit, mais rendant notre équipe superflue.
Notre réseau comptait environ 800 équipements, répartis sur 10 centres de données avec plus de 2,5 Tbps de bande passante disponible en sortie. Le matériel publié est donc un exemple substantiel de gestion d’un réseau de taille moyenne à l’aide d’Ansible. Nous avons laissé de côté la configuration de nos centres de données plus anciens pour rendre le résultat final plus lisible, tout en conservant suffisamment de substance pour ne pas en faire un exemple trivial.
Jerikan#
Le premier composant est Jerikan. En entrée, il prend une liste d’équipements, des données de configuration, des modèles et des scripts de validation. Il génère un ensemble de fichiers de configuration pour chaque appareil. Ansible pourrait effectuer cette tâche, mais il présente les limitations suivantes concernant la compilation des modèles :
- il est lent ;
- les erreurs sont difficiles à corriger1 ;
- la hiérarchie de recherche d’une variable est rigide.

Si vous voulez suivre les exemples, il vous suffit d’avoir installé Docker et Docker Compose. Clonez le dépôt et vous êtes prêt !
Source de vérité#
Nous utilisons des fichiers YAML, versionnés avec Git, comme source de vérité unique au lieu d’utiliser une base de données, comme NetBox, ou un mélange de base de données et de fichiers texte. Cela offre de nombreux avantages :
- chacun peut utiliser son éditeur de texte préféré ;
- l’équipe prépare les changements dans des branches ;
- l’équipe évalue les changements en utilisant des demandes de fusion ;
- les demandes de fusion présentent l’impact sur les fichiers de configuration générés ;
- le retour à un état antérieur est facile ;
- c’est rapide.
Mise à jour (11.2021)
Pour un argumentaire plus détaillé sur le choix de Git par rapport à NetBox, lisez « Git comme source de vérité pour l’automatisation du réseau »
Le premier fichier est devices.yaml. Il contient la
liste des équipements. Le deuxième fichier est
classifier.yaml. Il définit un ensemble de
clés-valeurs pour chaque équipement. Il est utilisé dans les modèles
et pour rechercher les données associées à un appareil.
$ ./run-jerikan scope to1-p1.sk1.blade-group.net continent: apac environment: prod groups: - tor - tor-bgp - tor-bgp-compute host: to1-p1.sk1 location: sk1 member: '1' model: dell-s4048 os: cumulus pod: '1' shorthost: to1-p1
Le nom de l’équipement est comparé à une liste d’expressions
régulières et chaque correspondance contribue au résultat. Pour
to1-p1.sk1.blade-group.net, le sous-ensemble suivant de
classifier.yaml définit ses variables :
matchers: - '^(([^.]*)\..*)\.blade-group\.net': environment: prod host: '\1' shorthost: '\2' - '\.(sk1)\.': location: '\1' continent: apac - '^to([12])-[as]?p(\d+)\.': member: '\1' pod: '\2' - '^to[12]-p\d+\.': groups: - tor - tor-bgp - tor-bgp-compute - '^to[12]-(p|ap)\d+\.sk1\.': os: cumulus model: dell-s4048
Le troisième fichier est searchpaths.py. Il décrit
les répertoires à examiner pour trouver une variable. Une fonction
Python fournit une liste de chemins dans data/ selon les
variables associées à l’équipement. Voici une version
simplifiée2 :
def searchpaths(scope): paths = [ "host/{scope[location]}/{scope[shorthost]}", "location/{scope[location]}", "os/{scope[os]}-{scope[model]}", "os/{scope[os]}", 'common' ] for idx in range(len(paths)): try: paths[idx] = paths[idx].format(scope=scope) except KeyError: paths[idx] = None return [path for path in paths if path]
Avec cette définition, les données pour to1-p1.sk1.blade-group.net
sont recherchées dans les chemins suivants :
$ ./run-jerikan scope to1-p1.sk1.blade-group.net […] Search paths: host/sk1/to1-p1 location/sk1 os/cumulus-dell-s4048 os/cumulus common
Les variables sont limitées à un espace de noms à spécifier lors d’une recherche. Nous utilisons les suivants :
systempour les comptes, DNS, serveurs syslog ;topologypour les ports, interfaces, adresses IP, sous-réseaux ;bgppour la configuration de BGP ;buildpour les modèles et les scripts de validation ;appspour les variables d’application.
Lors de la recherche d’une variable dans un espace de noms donné,
Jerikan recherche un fichier YAML nommé d’après l’espace de noms
dans chaque répertoire retourné par la fonction de recherche. Par
exemple, si nous recherchons une variable pour
to1-p1.sk1.blade-group.net dans l’espace de noms bgp, les fichiers
YAML suivants sont traités : host/sk1/to1-p1/bgp.yaml,
location/sk1/bgp.yaml, os/cumulus-dell-s4048/bgp.yaml,
os/cumulus/bgp.yaml et common/bgp.yaml. La recherche s’arrête à
la première correspondance.
Le fichier schema.yaml nous permet d’outrepasser ce
dernier comportement en fusionnant dans certains cas les dictionnaires
et les tableaux correspondants3. Voici un extrait de ce
fichier pour l’espace de noms topology :
system: users: merge: hash sampling: merge: hash ansible-vars: merge: hash netbox: merge: hash
La dernière fonctionnalité de la source de vérité est la possibilité
d’utiliser des modèles Jinja2 pour les clefs et les valeurs en les
préfixant par « ~ » :
# Dans data/os/junos/system.yaml netbox: manufacturer: Juniper model: "~{{ model|upper }}" # Dans data/groups/tor-bgp-compute/system.yaml netbox: role: net_tor_gpu_switch
Chercher netbox dans l’espace de noms system pour
to1-p2.ussfo03.blade-group.net produit le résultat suivant :
$ ./run-jerikan scope to1-p2.ussfo03.blade-group.net continent: us environment: prod groups: - tor - tor-bgp - tor-bgp-compute host: to1-p2.ussfo03 location: ussfo03 member: '1' model: qfx5110-48s os: junos pod: '2' shorthost: to1-p2 […] Search paths: […] groups/tor-bgp-compute […] os/junos common $ ./run-jerikan lookup to1-p2.ussfo03.blade-group.net system netbox manufacturer: Juniper model: QFX5110-48S role: net_tor_gpu_switch
Cela fonctionne aussi pour des données structurées :
# Dans groups/adm-gateway/topology.yaml interface-rescue: address: "~{{ lookup('topology', 'addresses').rescue }}" up: - "~ip route add default via {{ lookup('topology', 'addresses').rescue|ipaddr('first_usable') }} table rescue" - "~ip rule add from {{ lookup('topology', 'addresses').rescue|ipaddr('address') }} table rescue priority 10" # Dans groups/adm-gateway-sk1/topology.yaml interfaces: ens1f0: "~{{ lookup('topology', 'interface-rescue') }}"
Cela retourne le résultat suivant :
$ ./run-jerikan lookup gateway1.sk1.blade-group.net topology interfaces […] ens1f0: address: 121.78.242.10/29 up: - ip route add default via 121.78.242.9 table rescue - ip rule add from 121.78.242.10 table rescue priority 10
Pour placer des données dans la source de vérité, nous utilisons les règles suivantes :
- Ne pas se répéter.
- Préférer l’emplacement le plus spécifique sans enfreindre la première règle.
- Utiliser avec parcimonie les modèles, principalement pour respecter les règles précédentes.
- Limiter le modèle de données à ce qui est nécessaire pour votre cas d’utilisation.
La première règle est assez importante. Par exemple, lorsque vous spécifiez des adresses IP pour une liaison point à point, ne spécifiez qu’un côté et déduisez l’autre valeur via les modèles. La dernière règle signifie qu’il est inutile de reproduire un modèle BGP YANG pour spécifier les pairs et les politiques BGP :
peers: transit: cogent: asn: 174 remote: - 38.140.30.233 - 2001:550:2:B::1F9:1 specific-import: - name: ATT-US as-path: ".*7018$" lp-delta: 50 ix-sfmix: rs-sfmix: monitored: true asn: 63055 remote: - 206.197.187.253 - 206.197.187.254 - 2001:504:30::ba06:3055:1 - 2001:504:30::ba06:3055:2 blizzard: asn: 57976 remote: - 206.197.187.42 - 2001:504:30::ba05:7976:1 irr: AS-BLIZZARD
Modèles#
La liste des modèles à compiler pour chaque équipement est stockée
dans la source de vérité, sous l’espace de noms build :
$ ./run-jerikan lookup edge1.ussfo03.blade-group.net build templates data.yaml: data.j2 config.txt: junos/main.j2 config-base.txt: junos/base.j2 config-irr.txt: junos/irr.j2 $ ./run-jerikan lookup to1-p1.ussfo03.blade-group.net build templates data.yaml: data.j2 config.txt: cumulus/main.j2 frr.conf: cumulus/frr.j2 interfaces.conf: cumulus/interfaces.j2 ports.conf: cumulus/ports.j2 dhcpd.conf: cumulus/dhcp.j2 default-isc-dhcp: cumulus/default-isc-dhcp.j2 authorized_keys: cumulus/authorized-keys.j2 motd: linux/motd.j2 acl.rules: cumulus/acl.j2 rsyslog.conf: cumulus/rsyslog.conf.j2
Les modèles utilisent Jinja2. C’est le même moteur que pour
Ansible. Jerikan fournit quelques filtres personnalisés mais
réutilise également certains des filtres d’Ansible4,
notamment ipaddr. Voici un extrait de
templates/junos/base.j2 pour configurer
les serveurs DNS et NTP sur les équipements Juniper :
system { ntp { {% for ntp in lookup("system", "ntp") %} server {{ ntp }}; {% endfor %} } name-server { {% for dns in lookup("system", "dns") %} {{ dns }}; {% endfor %} } }
Voici le modèle équivalent pour Cisco IOS XR :
{% for dns in lookup('system', 'dns') %} domain vrf VRF-MANAGEMENT name-server {{ dns }} {% endfor %} ! {% for syslog in lookup('system', 'syslog') %} logging {{ syslog }} vrf VRF-MANAGEMENT {% endfor %} !
Trois fonctions utiles sont fournies :
devices()renvoie la liste des équipements correspondant à un ensemble de conditions. Par exemple,devices("location==ussfo03", "groups==tor-bgp")renvoie la liste des routeurs de San Francisco appartenant au groupetor-bgp. Vous pouvez également omettre l’opérateur si vous souhaitez que la valeur spécifiée soit égale à celle de l’équipement en cours. Par exemple,devices("location")renvoie les équipements situés dans le lieu actuel.lookup()effectue une recherche par clé. Elle prend l’espace de noms, la clé, et optionnellement, un nom d’équipement. S’il n’est pas fourni, la recherche s’effectue sur l’équipement actuel.scope()renvoie les variables associées à l’équipement indiqué.
Voici comment définir des sessions iBGP entre des routeurs situés dans le même centre de données :
{% for neighbor in devices("location", "groups==edge") if neighbor != device %} {% for address in lookup("topology", "addresses", neighbor).loopback|tolist %} protocols bgp group IPV{{ address|ipv }}-EDGES-IBGP { neighbor {{ address }} { description "IPv{{ address|ipv }}: iBGP to {{ neighbor }}"; } } {% endfor %} {% endfor %}
Nous disposons également d’une base de données clé-valeur pour
enregistrer les informations à réutiliser dans un autre modèle ou
équipement. Ceci est très utile pour construire automatiquement des
enregistrement DNS. Tout d’abord, on « capture » l’adresse IP insérée
dans un modèle avec le filtre store() :
interface Loopback0 description 'Loopback:' {% for address in lookup('topology', 'addresses').loopback|tolist %} ipv{{ address|ipv }} address {{ address|store('addresses', 'Loopback0')|ipaddr('cidr') }} {% endfor %} !
Puis, nous réutilisons les valeurs stockées pour construire les
enregistrements DNS en itérant sur les résultats de la fonction
store()5 :
{% for device, ip, interface in store('addresses') %} {% set interface = interface|replace('/', '-')|replace('.', '-')|replace(':', '-') %} {% set name = '{}.{}'.format(interface|lower, device) %} {{ name }}. IN {{ 'A' if ip|ipv4 else 'AAAA' }} {{ ip|ipaddr('address') }} {% endfor %}
Les modèles sont compilés localement avec ./run-jerikan build.
L’argument --limit restreint les équipements pour lesquels générer
des configurations. La construction ne se fait pas en parallèle car un
modèle peut dépendre des données collectées par un autre modèle.
Actuellement, il faut 1 minute pour construire environ 3000 fichiers
couvrant plus de 800 appareils.
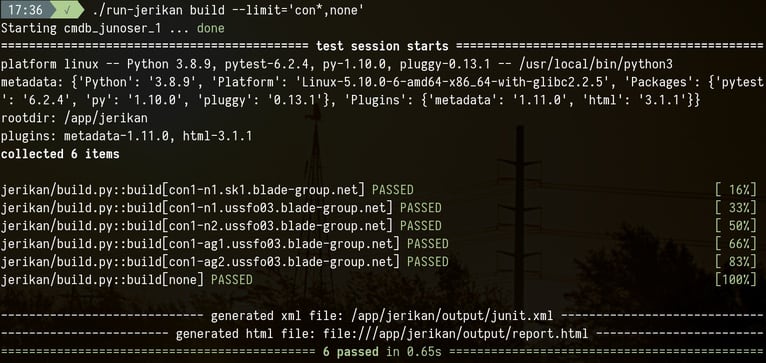
Lorsqu’une erreur se produit, une trace détaillée est affichée. Elle inclut le nom du modèle, le numéro de ligne et la valeur de toutes les variables visibles. C’est un gain de temps considérable par rapport à Ansible !
templates/opengear/config.j2:15: in top-level template code config.interfaces.{{ interface }}.netmask {{ infos.adddress | ipaddr("netmask") }} continent = 'us' device = 'con1-ag2.ussfo03.blade-group.net' environment = 'prod' host = 'con1-ag2.ussfo03' infos = {'address': '172.30.24.19/21'} interface = 'wan' location = 'ussfo03' loop = <LoopContext 1/2> member = '2' model = 'cm7132-2-dac' os = 'opengear' shorthost = 'con1-ag2' _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ value = JerkianUndefined, query = 'netmask', version = False, alias = 'ipaddr' […] # Check if value is a list and parse each element if isinstance(value, (list, tuple, types.GeneratorType)): _ret = [ipaddr(element, str(query), version) for element in value] return [item for item in _ret if item] > elif not value or value is True: E jinja2.exceptions.UndefinedError: 'dict object' has no attribute 'adddress'
Nous ne disposons pas de règles générales pour l’écriture des modèles.
Comme pour la source de vérité, il n’est pas nécessaire de créer des
modèles génériques capables de produire n’importe quelle configuration
BGP. Il y a un équilibre à trouver entre la lisibilité et le fait
d’éviter la duplication. Les modèles peuvent devenir effrayants et
complexes : parfois, il est préférable d’écrire un filtre ou une
fonction dans jerikan/jinja.py. Maîtriser
Jinja2 est un très bon investissement. Prenez le temps de
parcourir nos modèles, car certains d’entre eux
présentent des fonctionnalités intéressantes.
Validation#
Optionellement, chaque fichier de configuration peut être validé par
un script dans le répertoire checks/. Jerikan utilise la
variable checks dans l’espace de noms build pour connaître les
tests à appliquer :
$ ./run-jerikan lookup edge1.ussfo03.blade-group.net build checks - description: Juniper configuration file syntax check script: checks/junoser cache: input: config.txt output: config-set.txt - description: check YAML data script: checks/data.yaml cache: data.yaml
Dans l’exemple ci-dessus, checks/junoser est exécuté s’il y a une
modification du fichier généré config.txt. Il produit également une
version transformée du fichier de configuration qui est plus facile à
interfacer avec l’utilitaire diff. Junoser vérifie un fichier de
configuration Junos en utilisant la définition du schéma XML pour
Netconf6. En cas d’erreur, Jerikan affiche :
jerikan/build.py:127: RuntimeError -------------- Captured syntax check with Junoser call -------------- P: checks/junoser edge2.ussfo03.blade-group.net C: /app/jerikan O: E: Invalid syntax: set system syslog archive size 10m files 10 word-readable S: 1
Intégration continue avec GitLab#
L’étape suivante consiste à compiler les modèles en utilisant un
système d’intégration continue. Comme nous utilisons GitLab, Jerikan
contient un fichier .gitlab-ci.yml. Lorsque
nous devons effectuer un changement, nous créons une branche dédiée et
une demande de fusion. GitLab compile les modèles en utilisant le même
environnement que celui que nous utilisons sur nos ordinateurs
portables et les stocke dans un artefact.
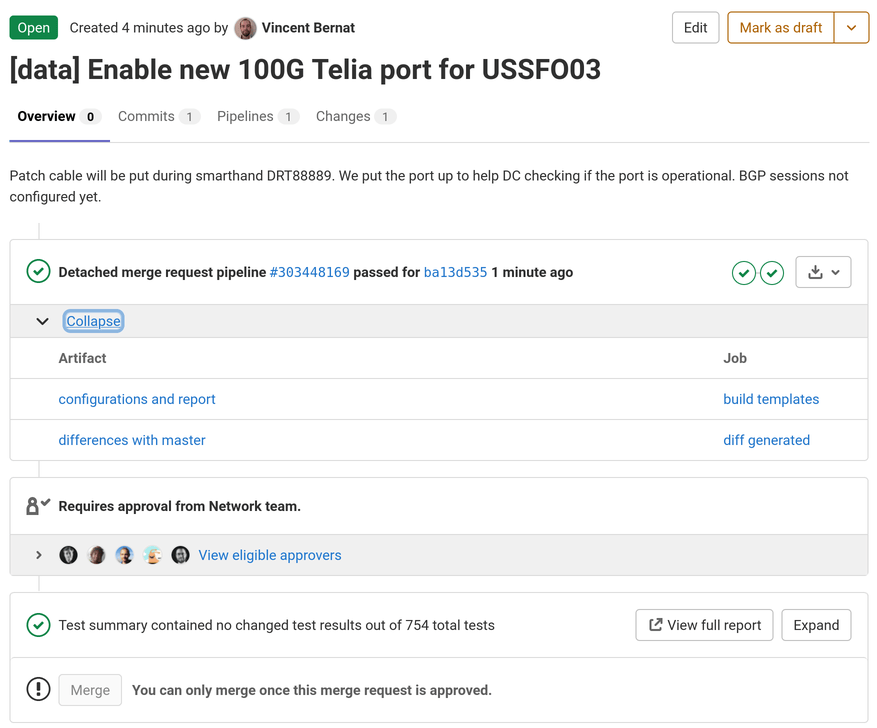
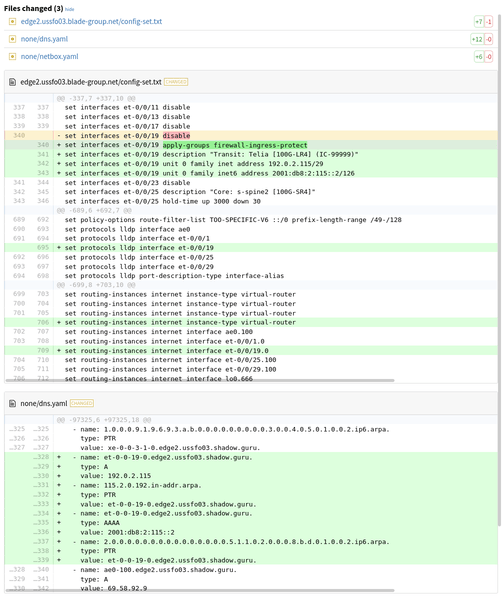
Avant d’approuver une fusion, un autre membre de l’équipe étudie les changements au niveau du code mais aussi les différences au niveau des fichiers générés :
Ansible#
Une fois que Jerikan a construit les fichiers de configuration, Ansible prend le relais. Il est également livré sous la forme d’une image Docker pour éviter la maintenance d’un environnement virtuel Python et s’assurer que nous utilisons tous les mêmes versions.
Inventaire#
Jerikan a généré un fichier d’inventaire. Il contient tous les équipements gérés, des variables définies pour chacun d’eux et les groupes convertis en groupes Ansible :
ob1-n1.sk1.blade-group.net ansible_host=172.29.15.12 ansible_user=blade ansible_connection=network_cli ansible_network_os=ios ob2-n1.sk1.blade-group.net ansible_host=172.29.15.13 ansible_user=blade ansible_connection=network_cli ansible_network_os=ios ob1-n1.ussfo03.blade-group.net ansible_host=172.29.15.12 ansible_user=blade ansible_connection=network_cli ansible_network_os=ios none ansible_connection=local [oob] ob1-n1.sk1.blade-group.net ob2-n1.sk1.blade-group.net ob1-n1.ussfo03.blade-group.net [os-ios] ob1-n1.sk1.blade-group.net ob2-n1.sk1.blade-group.net ob1-n1.ussfo03.blade-group.net [model-c2960s] ob1-n1.sk1.blade-group.net ob2-n1.sk1.blade-group.net ob1-n1.ussfo03.blade-group.net [location-sk1] ob1-n1.sk1.blade-group.net ob2-n1.sk1.blade-group.net [location-ussfo03] ob1-n1.ussfo03.blade-group.net [in-sync] ob1-n1.sk1.blade-group.net ob2-n1.sk1.blade-group.net ob1-n1.ussfo03.blade-group.net none
in-sync est un groupe spécial pour les équipements dont la
configuration doit correspondre à la configuration générée.
Quotidiennement et sans surveillance, Ansible devrait être capable
de pousser les configurations vers ce groupe. L’objectif à moyen terme
est de couvrir tous les équipements.
none est un équipement spécial pour les tâches non liées à un hôte
spécifique. Cela inclut la synchronisation de NetBox, des objets IRR et du DNS, la mise à jour de la
RPKI et la construction des fichiers de géolocalisation.
Playbook#
Nous utilisons un unique playbook pour tous les équipements. Il est
décrit dans le fichier
ansible/playbooks/site.yaml. En voici
une version raccourcie :
- hosts: adm-gateway:!done strategy: mitogen_linear roles: - blade.linux - blade.adm-gateway - done - hosts: os-linux:!done strategy: mitogen_linear roles: - blade.linux - done - hosts: os-junos:!done gather_facts: false roles: - blade.junos - done - hosts: os-opengear:!done gather_facts: false roles: - blade.opengear - done - hosts: none:!done gather_facts: false roles: - blade.none - done
Un hôte n’exécute qu’un seul des rôles. Par exemple, un équipement
Junos exécute le rôle blade.junos. Une fois qu’un rôle a été
exécuté, l’équipement est ajouté au groupe done et les autres rôles
sont ignorés.
Le playbook peut être exécuté avec les fichiers de configuration
générés par GitLab en utilisant la commande ./run-ansible-gitlab.
Elle utilise Docker pour exposer la commande ansible-playbook et
elle accepte les mêmes arguments. Pour simuler un déploiement de la
configuration sur les équipements du centre de données SK1, nous
utilisons :
$ ./run-ansible-gitlab playbooks/site.yaml --limit='edge:&location-sk1' --diff --check […] PLAY RECAP ************************************************************* edge1.sk1.blade-group.net : ok=6 changed=0 unreachable=0 failed=0 skipped=3 rescued=0 ignored=0 edge2.sk1.blade-group.net : ok=5 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
Nous avons quelques règles pour écrire les rôles :
--checkdoit détecter si un changement est nécessaire,--diffdoit fournir une visualisation des changements prévus,--checket--diffne doivent rien afficher s’il n’y a rien à changer,- écrire un module sur mesure pour nos besoins est une solution valable,
- toute la configuration de l’équipement est gérée7,
- les secrets doivent être stockés dans Vault,
- les modèles doivent être évités car nous avons Jerikan pour cela,
- les tâches doivent être réutilisées et non dupliquées8.
Nous évitons d’utiliser des collections d’Ansible Galaxy, à
l’exception de celles permettant de se connecter et d’interagir avec
les équipements constructeur, comme la collection
cisco.iosxr. La qualité des collections d’Ansible
Galaxy est assez aléatoire et cela représente un effort de
maintenance supplémentaire. Nous préférons écrire des rôles adaptés à
nos besoins. Les collections que nous utilisons sont dans
ci/ansible/ansible-galaxy.yaml. Nous
utilisons Mitogen pour accélérer considérablement les exécutions
d’Ansible sur les hôtes Linux.
Nous disposons également de quelques playbooks à des fins opérationnelles : mise à niveau d’une version, isolation d’un routeur Internet, etc. Nous avions également en tête d’ajouter une étape de validation dans les rôles : est-ce que toutes les sessions BGP sont opérationnelles ? Cela aurait permis de valider un déploiement et de revenir rapidement en arrière en cas de problèmes.
Actuellement, nos playbooks sont exécutés à partir de nos ordinateurs
portables. Pour assurer le suivi des exécutions, nous utilisons
ARA. Un essai hebdomadaire sur les équipements du groupe in-sync
fournit également un tableau de bord sur les hôtes sur lesquels nous
devons faire converger la configuration.
Données de configuration et modèles#
Nous livrons Jerikan avec des données et des modèles correspondant à la configuration de nos centres de données USSFO03 et SK1. Ils n’existent plus mais, nous vous le promettons, tout ceci était utilisé en production à une époque ! 😢
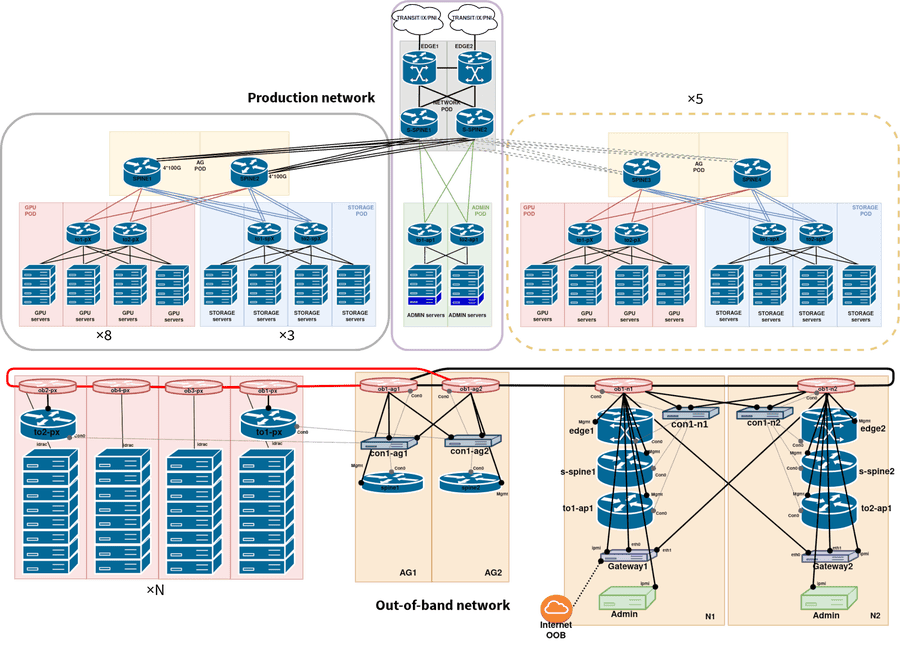
Vous trouverez la configuration pour :
- Nos routeurs Internet
- Certains fonctionnent sur Junos, comme edge2.ussfo03, les autres sur IOS XR, comme edge1.sk1. Les fonctionnalités implémentées sont similaires dans les deux cas et nous pouvons échanger l’un contre l’autre. Il y a la configuration BGP pour les transits, les peerings et les IX ainsi que les politiques BGP associées. PeeringDB est interrogé pour obtenir le nombre maximum de préfixes à accepter. bgpq3 et un IRRd conteneurisé aident à filtrer les routes reçues. Un pare-feu est également présent. IPv4 et IPv6 sont tous deux configurés.
- Notre fabrique BGP
- BGP est utilisé à l’intérieur du centre de données9 et s’étend jusqu’aux hôtes physiques. La configuration est automatiquement dérivée de l’emplacement du dispositif et du numéro de port10. Les switchs en haut de chaque rack utilisent des sessions BGP passives pour les ports vers les serveurs. Ils exposent également un réseau spécifique pour permettre de démarrer en utilisant DHCP et PXE. Ils font également office de serveur DHCP. La conception est multivendeur : certains équipements fonctionnent sous Cumulus Linux, comme to1-p1.ussfo03, tandis que d’autres fonctionnent sous Junos, comme to1-p2.ussfo03.
- Notre réseau hors bande
- Nous utilisons des commutateurs Cisco Catalyst 2960 pour construire un réseau hors bande L2. Pour assurer la redondance et économiser quelques sous sur le câblage, nous construisons des petites boucles et exploitons le protocole STP. Regardez ob1-p1.ussfo03. Le réseau est connecté de manière redondante à des serveurs d’accès. Nous utilisons également des équipements OpenGear pour les accès console. Regardez con1-n1.ussfo03.
- Nos passerelles d’accès
- Ces serveurs Linux ont plusieurs objectifs : passerelles SSH, connexion de secours, accès direct au réseau hors bande, installation automatisée des équipements réseau11, accès Internet pour les flux administratifs, centralisation des serveurs de console à l’aide de Conserver et mise à disposition d’une API pour l’autoconfiguration des sessions BGP pour les serveurs physiques. Ce sont les premiers serveurs installés dans un nouveau centre de données et ils sont utilisés pour mettre en place tout le reste. Regardez à la fois les fichiers générés et les tâches Ansible associées.
Mise à jour (10.2021)
J’ai donné une présentation de Jerikan et Ansible durant le FRnOG #34. Elle reprend essentiellement le contenu de cet article.