Akvorado: a flow collector, enricher, and visualizer
Vincent Bernat
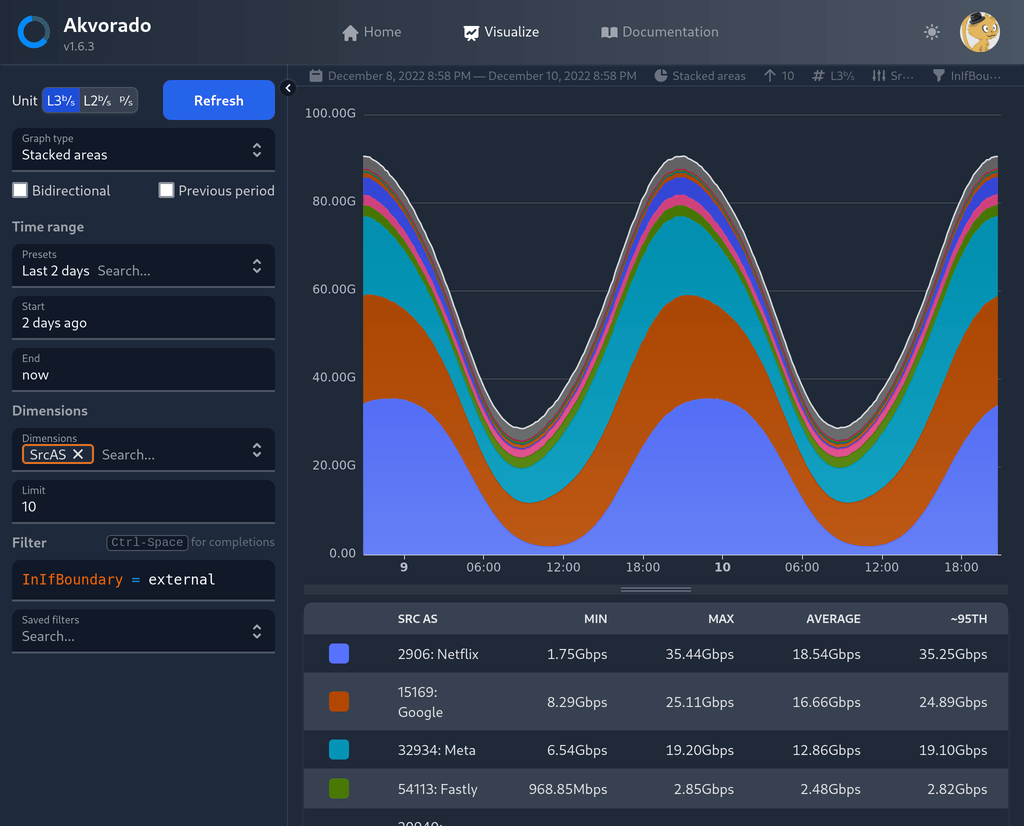
Earlier this year, we released Akvorado, a flow collector, enricher, and visualizer. It receives network flows from your routers using either NetFlow v9, IPFIX, or sFlow. Several pieces of information are added, like GeoIP and interface names. The flows are exported to Apache Kafka, a distributed queue, then stored inside ClickHouse, a column-oriented database. A web frontend is provided to run queries. A live version is available for you to play with.
Several alternatives exist:
- Kentik, a popular cloud-based solution,
- ElastiFlow, a self-hosted proprietary solution, or
- your own assembly of open source solutions by picking a flow collector (pmacct, GoFlow2, or vFlow), a distributed queue1 (Apache Kafka or RabbitMQ), a database (ClickHouse, Elasticsearch, or Apache Pinot), and a web frontend (Grafana, Kibana, or Apache Superset).
Akvorado differentiates itself from these solutions because:
- it is open source (licensed under the AGPLv3 license), and
- it bundles flow collection, storage, and a web interface into a single “product.”
The proposed deployment solution relies on Docker Compose to set up Akvorado, Zookeeper, Kafka, and ClickHouse. I hope it should be enough for anyone to get started quickly. Akvorado is performant enough to handle 100 000 flows per second with 64 GB of RAM and 24 vCPU. With 2 TB of disk, you should expect to keep data for a few years.
I spent some time writing fairly complete documentation. It seems redundant to repeat its content in this blog post. There is also a section about its internal design if you are interested in how it is built. I also did a FRnOG presentation earlier this year, and a ClickHouse meetup presentation, which focuses more on how ClickHouse is used. I plan to write more detailed articles on specific aspects of Akvorado. Stay tuned! 📻