Compression des fichiers embarqués dans Go
Vincent Bernat
3 minutes de lecture
Aussi disponible en
Classé dans
Document lié :
La fonctionnalité embed de Go permet d’intégrer des ressources statiques dans un exécutable, mais elle les stocke non compressées. Cela gaspille de l’espace : une interface web avec de la documentation peut faire gonfler un binaire de plusieurs mégaoctets. Une proposition pour activer optionnellement la compression a été déclinée car il est difficile de gérer tous les cas d’usage. Une solution ? Mettre toutes les ressources dans une archive ZIP ! 🗜️
Code#
La bibliothèque standard de Go inclut un module pour lire et écrire des
archives ZIP. Il contient une fonction qui transforme une archive ZIP en une
structure io/fs.FS. Cette dernière peut remplacer
embed.FS dans la plupart des cas1.
package embed
import (
"archive/zip"
"bytes"
_ "embed"
"fmt"
"io/fs"
"sync"
)
//go:embed data/embed.zip
var embeddedZip []byte
var dataOnce = sync.OnceValue(func() *zip.Reader {
r, err := zip.NewReader(bytes.NewReader(embeddedZip), int64(len(embeddedZip)))
if err != nil {
panic(fmt.Sprintf("cannot read embedded archive: %s", err))
}
return r
})
func Data() fs.FS {
return dataOnce()
}
Pour construire l’archive embed.zip, nous pouvons utiliser une règle dans un
Makefile. Les fichiers à y placer sont spécifiés comme des dépendances pour
s’assurer que les changements sont détectés. La variable automatique $@
est la cible de la règle, tandis que $^ est remplacée par la liste des
dépendances, modifiées ou non.
common/embed/data/embed.zip: console/data/frontend console/data/docs
common/embed/data/embed.zip: orchestrator/clickhouse/data/protocols.csv
common/embed/data/embed.zip: orchestrator/clickhouse/data/icmp.csv
common/embed/data/embed.zip: orchestrator/clickhouse/data/asns.csv
common/embed/data/embed.zip:
mkdir -p common/embed/data && zip --quiet --recurse-paths --filesync $@ $^
Gain d’espace#
Akvorado, un collecteur de flux écrit en Go, embarque plusieurs ressources statiques :
- des fichiers CSV pour traduire les numéros de ports, les protocoles ou les numéros d’AS ;
- du HTML, CSS, JS et des images pour l’interface web ;
- la documentation.
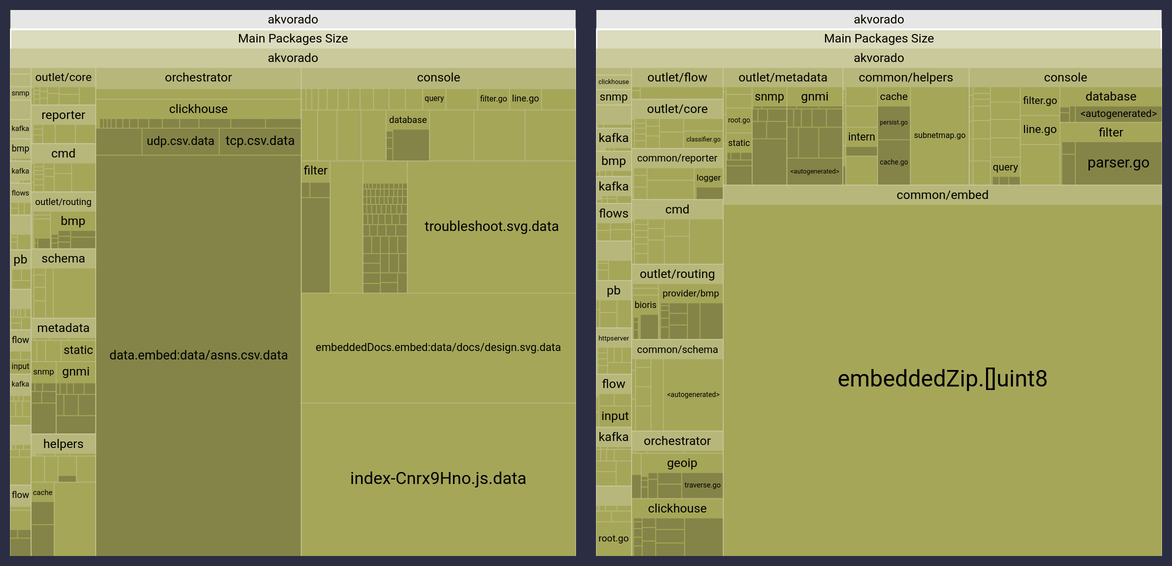
embed.zip.L’intégration de ces ressources dans une archive ZIP a réduit la taille de l’exécutable de plus de 4 Mio :
$ unzip -p common/embed/data/embed.zip | wc -c | numfmt --to=iec
7.3M
$ ll common/embed/data/embed.zip
-rw-r--r-- 1 bernat users 2.9M Dec 7 17:17 common/embed/data/embed.zip
Perte de performance#
Lire depuis une archive compressée n’est pas aussi rapide que lire un fichier à plat. Un benchmark simple montre que c’est plus de 4 fois plus lent. De plus, la lecture de l’archive alloue de la mémoire2.
goos: linux
goarch: amd64
pkg: akvorado/common/embed
cpu: AMD Ryzen 5 5600X 6-Core Processor
BenchmarkData/compressed-12 2262 526553 ns/op 610 B/op 10 allocs/op
BenchmarkData/uncompressed-12 9482 123175 ns/op 0 B/op 0 allocs/op
Chaque accès à une ressource nécessite une étape de décompression, comme on peut le voir dans ce graphique :
Bien qu’une archive ZIP ait un index pour trouver rapidement le fichier demandé,
se déplacer à l’intérieur d’un fichier compressé n’est actuellement pas
possible3. Par conséquent, les fichiers retournés depuis une archive
compressée n’implémentent pas les interfaces io.ReaderAt ou io.Seeker,
contrairement aux fichiers directement embarqués. Cela empêche certaines
fonctionnalités du serveur HTTP, comme servir des fichiers partiels ou détecter
le type MIME.
Pour Akvorado, c’est un compromis acceptable pour économiser quelques mébioctets d’un exécutable de presque 100 Mio. La semaine prochaine, je continuerai cette aventure futile en expliquant comment j’ai empêché Go de désactiver l’élimination de code mort ! 🦥