lanĉo: a task launcher powered by cgroups
Vincent Bernat
Update (2021-07)
lanĉo does not work with cgroups v2, which are now enabled by default on modern distributions. There is no plan to update it. A good alternative is systemd-run.
A few months ago, I was looking for a piece of software to spawn long-running tasks on behalf of some daemon with the benefit of the tasks not being interrupted when this daemon is restarted. Here are the specifications:
- No special privilege is needed to submit a task.
- Submitted tasks are not known beforehand.
- Task output is redirected to a log file.
- Submitted tasks are identified by a provided name.
- With only the name as a reference, a task can be checked for existence or killed.
- Tasks should not be interrupted by an unrelated event, like a configuration change or a software upgrade.
The last requirement explains why tasks are not spawned directly by the daemon requesting them: its complexity or the way it needs to be operated may need frequent restarts. Even if it is possible to re-execute a daemon while keeping its children, like stateful re-exec support in Upstart, this is quite difficult: internal state should be serialized and restored. Part of this state can be contained into a third-party library.
While Upstart or systemd seemed to be good candidates for this purpose, I didn’t find a straightforward way to run arbitrary tasks without any privilege.1
Here comes lanĉo.2 It is a very simple task launcher. It can run any tasks, stop them and check if they are still running. It leverages cgroups in recent Linux kernels and avoids the use of any daemon.
Quick tour#
Before looking at how lanĉo works, let’s have a look at how it can be used. To avoid usage conflicts, each task is run in the context of a namespace that needs to be initialized:
$ sudo lanco testns init -u $(id -un) -g $(id -gn)
This is the only command that needs to be run as root. Subsequent ones can be run as a normal user. Let’s run some task:
$ lanco testns run first-task openssl speed aes
$ lanco testns check first-task && echo "Still running"
Still running
$ lanco testns ls
testns
├ first-task
│ → 28456 openssl speed aes
╯
The output of the task is logged into a file:
$ head -3 /var/log/lanco-testns/task-first-task.log
Doing aes-128 cbc for 3s on 16 size blocks: 8678442 aes-128 cbc's in 2.85s
Doing aes-128 cbc for 3s on 64 size blocks: 2478283 aes-128 cbc's in 2.99s
Doing aes-128 cbc for 3s on 256 size blocks: 628105 aes-128 cbc's in 3.00s
If the task is too long, we can kill it:
$ lanco testns run first-task openssl speed aes
$ lanco testns stop first-task
You cannot run a task that already exists or kill a task that does not exist:
$ lanco testns run first-task openssl speed aes
2013-06-09T22:50:34 [WARN/run] task first-task is already running
$ lanco testns stop second-task
2013-06-09T22:50:45 [WARN/stop] task second-task is not running
Thanks to the use of cgroups, lanĉo is able to track multiple processes even when they are forking away:3
$ lanco testns run second-task sh -c \
> "while true; do (sleep 30 &)& sleep 1; done"
$ lanco testns ls
testns
├ first-task
│ → 28456 openssl speed aes
├ second-task
│ → 29572 sh -c while true; do (sleep 30 &)& sleep 1; done
│ → 29575 sleep 30
│ → 29593 sleep 30
│ → 29596 sleep 30
│ → 29599 sleep 30
│ → 29622 sleep 30
│ → 29644 sleep 1
│ → 29645 sleep 30
╯
$ lanco testns stop second-task
$ lanco testns check second-task || echo "Killed!"
Killed!
Also, there is a top-like command (lanco testns top):
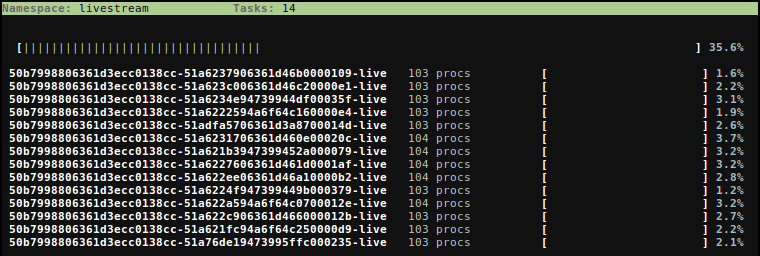
Using cgroups#
Control groups (cgroups) is a mechanism to partition a set of tasks and their future children into hierarchical groups with a set of parameters.
Hierarchy#
Let’s start with the hierarchical stuff first. To create a new
hierarchy, you have to mount the cgroup filesystem on some empty
directory. Usually, cgroups hierarchies are setup in
/sys/fs/cgroups which is a tmpfs filesystem:
# mount -t tmpfs tmpfs /sys/fs/cgroup -o nosuid,nodev,noexec,relatime,mode=755
Now, we can create our first hierarchy:
# cd /sys/fs/cgroup
# mkdir my-first-hierarchy
# mount -t cgroup cgroup my-first-hierarchy -o name=my-first-hierarchy,none
# ls -1 my-first-hierarchy
cgroup.clone_children
cgroup.event_control
cgroup.procs
notify_on_release
release_agent
tasks
We will see later the purpose of none. The most interesting file is
tasks. It contains the PIDs of all processes in our group. Since
there are currently no sub-groups, all processes are part of it. Let’s
create a sub-group and attach a process to it:
# mkdir first-child
# cd first-child
# ls -1
cgroup.clone_children
cgroup.event_control
cgroup.procs
notify_on_release
tasks
# echo $$ > tasks
# cat tasks
23184
23311
# cat /proc/$$/cgroup
9:name=my-first-hierarchy:/first-child
8:perf_event:/
7:blkio:/
6:net_cls:/
5:freezer:/
4:devices:/
3:cpuacct,cpu:/
2:cpuset:/
1:name=systemd:/user/bernat/1
We have added our shell to the new cgroup. Moreover, all its
children will also be part of this group. This explains why we have
two tasks: the shell and cat. The last command is quite interesting:
for each hierarchy, it shows which cgroup the task belongs to. For a
given hierarchy, each task is exactly in one group.
The most useful features of lanĉo are done using just this: a namespace is a named hierarchy and each task is enclosed into a cgroup so it can be tracked properly.
Subsystems#
A subsystem makes use of the task grouping provided by cgroups to assign resources to a set of tasks. Each available subsystem can only be in one hierarchy, so the usual way to setup things is to assign a hierarchy for each subsystem.4
Let’s have a look at the cpuset subsystem: it allows one to assign tasks
to specific CPUs and memory nodes (for NUMA systems). Suppose we
have 4 cores and we want to assign the first core to common system
tasks and the three remaining ones to nginx:
# cd /sys/fs/cgroup
# mkdir cpuset
# mount -t cgroup cgroup cpuset -o cpuset
# echo 0-3 > cpuset/cpuset.cpus
# echo 0 > cpuset/cpuset.mems
# mkdir cpuset/system
# echo 0 > cpuset/system/cpuset.cpus
# echo 0 > cpuset/system/cpuset.mems
# for task in $(cat cpuset/tasks); do
> echo $task > cpuset/system/tasks
> done
# mkdir cpuset/nginx
# echo 1-3 > cpuset/nginx/cpuset.cpus
# echo 0 > cpuset/nginx/cpuset.mems
# for task in $(pidof nginx); do
> echo $task > cpuset/nginx/tasks
> done
The first mount is not needed if something else (like systemd) has
setup the appropriate subsystem. Now, even if some system process is
going crazy, it won’t affect the performance of your webserver.
The kernel comes with a more complete documentation if you need additional details on cgroups. There are high level tools to manipulate them, like the tools provided by libcg, but they are currently quite buggy and invasive.
Use in lanĉo#
Here are the features used by lanĉo:
- For each namespace, a specific named hierarchy is created.
- By setting the appropriate permissions on the hierarchy, an unprivileged user can create subgroups.
- Each submitted task has its own sub-group for tracking purpose.
- Actions can be executed when a task terminates by using the release agent mechanism.5
- The
cpuacctsubsystem is used to track CPU usage: a group is created in this subsystem for this purpose.