lldpd 0.7.1
Vincent Bernat
Il y a quelques semaines, une nouvelle version de lldpd, une implémentation de 802.1AB (norme aussi connue sous le nom LLDP), a été publiée.
LLDP est un protocole destiné à remplacer d’autres protocoles de niveau 2 tels que EDP et CDP. Son but est de fournir un mécanisme standard pour envoyer des informations aux périphériques réseau voisins.
De manière plus pragmatique, LLDP permet de savoir exactement sur quel port est branché un serveur (et réciproquement). Pour illustrer son usage, j’ai réalisé quelques images à la xkcd:
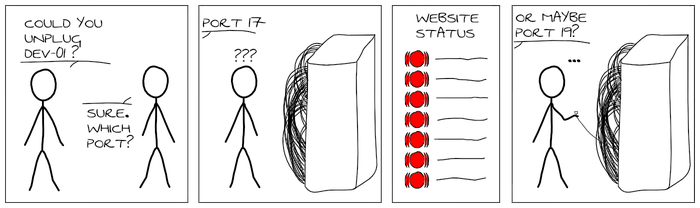
Pour plus d’informations sur lldpd, rendez-vous sur le nouveau site web qui lui est dédié. Ce journal est destiné à présenter les grands changements techniques qui ont affectés lldpd depuis la précédente version majeure sortie il y a un an.
Version & journal des modifications#
Mise à jour (02.2013)
Guillem Jover m’a indiqué comment il
avait fait pour libbsd. D’abord, sauvegarder la version issue de
git dans .dist-version et la réutiliser si elle existe. Cela
permet de pouvoir reconstruire le ./configure à partir de l’archive
publiée sans perdre la version, ce qui permet de répondre à la
critique de Thorsten Glaser sans perdre en souplesse. Ensuite,
inclure le fichier CHANGELOG dans DISTCLEANFILES. C’est une
meilleure façon de faire que j’ai donc adoptée. Les deux
sections suivantes sont donc en partie obsolètes dans leur réalisation
technique.
Version automatique#
Le numéro de version était précédemment en dur dans le fichier
configure.ac. Il fallait donc penser à modifier la ligne
correspondante avant chaque publication :
AC_INIT([lldpd], [0.5.7], [bernat@luffy.cx])
Cette information est déjà présente dans l’arbre git et il est donc possible de l’en extraire automatiquement de manière assez simple :
AC_INIT([lldpd],
[m4_esyscmd_s([git describe --tags --always --match [0-9]* 2> /dev/null || date +%F])],
[bernat@luffy.cx])
Si HEAD est étiqueté 0.7.1, ce sera exactement ce numéro de
version qui sera utilisé. Sinon, l’étiquette la plus proche est
utilisée suivie du nombre de commits depuis celle-ci ainsi que du hash
courant. Par exemple : 0.7.1-29-g2909519.
Pour que cela fonctionne, il est donc nécessaire de générer le
./configure depuis l’arbre git et non depuis l’archive finale qui
ne contient plus cette information.
Construction du journal des modifications#
La construction automatique du journal des modifications à partir de
l’arbre git est une pratique assez répandue. Il y a toutefois
quelques subtilités pour l’intégrer correctement dans le processus de
publication. Voici ma tentative avec l’aide de automake :
dist_doc_DATA = README.md NEWS ChangeLog .PHONY: $(distdir)/ChangeLog dist-hook: $(distdir)/ChangeLog $(distdir)/ChangeLog: $(AM_V_GEN)if test -d $(top_srcdir)/.git; then \ prev=$$(git describe --tags --always --match [0-9]* 2> /dev/null) ; \ for tag in $$(git tag | grep -E '^[0-9]+(\.[0-9]+){1,}$$' | sort -rn); do \ if [ x"$$prev" = x ]; then prev=$$tag ; fi ; \ if [ x"$$prev" = x"$$tag" ]; then continue; fi ; \ echo "$$prev [$$(git log $$prev -1 --pretty=format:'%ai')]:" ; \ echo "" ; \ git log --pretty=' - [%h] %s (%an)' $$tag..$$prev ; \ echo "" ; \ prev=$$tag ; \ done > $@ ; \ else \ touch $@ ; \ fi ChangeLog: touch $@
Les entrées sont groupées par version. Je maintiens manuellement un
résumé des modifications les plus importantes dans un fichier NEWS.
Cœur#
C99#
J’ai récemment lu le livre 21st Century C qui est globalement très positif. J’ai depuis adopté l’initialisation des membres d’une structure lors de la déclaration. Étant donné qu’il s’agit également d’une extension de GCC depuis longtemps, cela ne représente pas un problème de compatibilité majeur.
Sans cette fonctionnalité :
struct netlink_req req; struct iovec iov; struct sockaddr_nl peer; struct msghdr rtnl_msg; memset(&req, 0, sizeof(req)); memset(&iov, 0, sizeof(iov)); memset(&peer, 0, sizeof(peer)); memset(&rtnl_msg, 0, sizeof(rtnl_msg)); req.hdr.nlmsg_len = NLMSG_LENGTH(sizeof(struct rtgenmsg)); req.hdr.nlmsg_type = RTM_GETLINK; req.hdr.nlmsg_flags = NLM_F_REQUEST | NLM_F_DUMP; req.hdr.nlmsg_seq = 1; req.hdr.nlmsg_pid = getpid(); req.gen.rtgen_family = AF_PACKET; iov.iov_base = &req; iov.iov_len = req.hdr.nlmsg_len; peer.nl_family = AF_NETLINK; rtnl_msg.msg_iov = &iov; rtnl_msg.msg_iovlen = 1; rtnl_msg.msg_name = &peer; rtnl_msg.msg_namelen = sizeof(struct sockaddr_nl);
Et avec cette fonctionnalité :
struct netlink_req req = { .hdr = { .nlmsg_len = NLMSG_LENGTH(sizeof(struct rtgenmsg)), .nlmsg_type = RTM_GETLINK, .nlmsg_flags = NLM_F_REQUEST | NLM_F_DUMP, .nlmsg_seq = 1, .nlmsg_pid = getpid() }, .gen = { .rtgen_family = AF_PACKET } }; struct iovec iov = { .iov_base = &req, .iov_len = req.hdr.nlmsg_len }; struct sockaddr_nl peer = { .nl_family = AF_NETLINK }; struct msghdr rtnl_msg = { .msg_iov = &iov, .msg_iovlen = 1, .msg_name = &peer, .msg_namelen = sizeof(struct sockaddr_nl) };
Journaux#
La journalisation de lldpd était assez pauvre. Généralement, pour
répondre à un rapport de bug, je demandais à l’auteur d’ajouter
quelques printf() par-ci, par-là. J’ai ajouté des appels à
log_debug() à de nombreux endroits ainsi qu’une possibilité de
filtre. Par exemple, pour obtenir des informations détaillées sur la
découverte des interfaces, il est possible de lancer lldpd avec les
arguments -ddd -D interface.
De plus, la sortie sur un terminal est faite en couleurs. Cela peut paraître futile, mais il est beaucoup plus aisé de repérer rapidement les erreurs et les avertissements de cette façon.
libevent#
lldpd 0.5.7 utilisait sa propre boucle d’évènements à base de
select(). Cela ne posait pas de problèmes particuliers mais je ne
voulais pas étendre cette boucle pour aboutir à une boucle
d’évènements complète alors qu’il existe des bibliothèques solides
dédiées à cet usage. J’ai donc remplacé celle-ci par libevent.
La version minimale de libevent requise est la 2.0.5. Le site Upstream Tracker permet de consulter les changements d’API et d’ABI d’une bibliothèque et donc de vérifier la version nécessaire. Cette version de libevent n’est pas disponible dans de nombreuses distributions. Par exemple, Debian Squeeze et Ubuntu Lucid n’ont que la version 1.4.13. Je tente également de maintenir la compatibilité avec des distributions beaucoup plus anciennes, telles que RHEL 2, qui peuvent ne pas avoir libevent du tout.
Pour certains utilisateurs, compiler une bibliothèque tierce préalablement à la compilation d’un logiciel est pénible. Aussi, j’ai inclus le code source de libevent dans lldpd (en tant que sous-module git). Il n’est utilisé que si la version présente sur le système n’est pas suffisamment récente.
Jetez un œil sur m4/libevent.m4 et
src/daemon/Makefile.am pour comprendre
comment est réalisée cette inclusion conditionnelle.
Client#
Sérialisation#
Afin d’afficher les voisins découverts par lldpd, lldpctl
communique avec ce dernier via une socket Unix. Chaque structure
devant être sérialisée était décrite avec une chaîne de
caractères. Par exemple :
#define STRUCT_LLDPD_DOT3_MACPHY "(bbww)" struct lldpd_dot3_macphy { u_int8_t autoneg_support; u_int8_t autoneg_enabled; u_int16_t autoneg_advertised; u_int16_t mau_type; };
Je ne voulais pas utiliser de bibliothèques telles que Protocol Buffers car elles nécessitent l’utilisation d’une structure intermédiaire dans laquelle il aurait fallu copier les données.
Toutefois, le processus de sérialisation de lldpd ne permettait pas de gérer les pointeurs vers d’autres structures, les listes ou les références circulaires. J’ai donc écrit une version plus avancée utilisant des annotations à l’aide de macros :
struct lldpd_chassis { TAILQ_ENTRY(lldpd_chassis) c_entries; u_int16_t c_index; u_int8_t c_protocol; u_int8_t c_id_subtype; char *c_id; int c_id_len; char *c_name; char *c_descr; u_int16_t c_cap_available; u_int16_t c_cap_enabled; u_int16_t c_ttl; TAILQ_HEAD(, lldpd_mgmt) c_mgmt; }; MARSHAL_BEGIN(lldpd_chassis) MARSHAL_TQE (lldpd_chassis, c_entries) MARSHAL_FSTR (lldpd_chassis, c_id, c_id_len) MARSHAL_STR (lldpd_chassis, c_name) MARSHAL_STR (lldpd_chassis, c_descr) MARSHAL_SUBTQ(lldpd_chassis, lldpd_mgmt, c_mgmt) MARSHAL_END;
Seuls les pointeurs doivent être annotés. Le reste de la structure est
simplement copiée avec memcpy()1. Je suis encore assez
partagé sur le résultat et il est sans doute possible d’améliorer les
choses. En vrac : mettre les annotations directement dans la
structure, utiliser un parseur de code C ou utiliser la
sortie AST de LLVM…
Bibliothèque#
lldpd 0.5.7 disposait de deux points d’entrée pour interagir avec
lldpd :
- À travers le support SNMP. Seules les informations contenues dans la LLDP-MIB sont alors exportées. Les aspects spécifiques à l’implémentation ne sont donc pas disponibles. De plus, le support est actuellement en lecture seulement.
- À travers
lldpctl. Grâce à une contribution de Andreas Hofmeister, la sortie peut être produite sous forme d’un document XML.
L’intégration de lldpd dans une pile réseau était donc limitée à l’un de ces deux canaux. À titre d’exemple, il est possible de regarder comment Vyatta a effectué cette intégration à l’aide de la seconde solution.
Afin de fournir une solution plus robuste, une bibliothèque partagée,
liblldpctl, existe désormais. J’ai suivi les grandes directions
suivantes dans sa conception2 :
- Une convention de nommage uniforme. Tous les symboles exportés sont
préfixés par
lldpctl_. Pas de pollution de l’espace de noms. - Une convention des valeurs de retour uniforme. En cas d’erreurs, les
fonctions retournant des pointeurs retournent
NULL, celles retournant des entiers retournent-1. - Pas de variables globales. Réentrant et possibilité d’utiliser des threads.
- Un seul fichier d’entête bien documenté.
- Une API asynchrone pour les entrées/sorties. La bibliothèque délègue ces dernières à l’utilisateur en lui demandant de fournir les fonctions nécessaires. Ces dernières peuvent retarder leurs effets. Dans ce cas, l’utilisateur doit appeler des fonctions particulières de la bibliothèque quand les données deviennent disponibles. L’intégration dans une boucle d’évènement existante est alors triviale. Une fine couche synchrone est également fournie.
- Des types opaques avec des fonctions d’accès.
L’accès aux informations est fait à travers un « atome » qui est un
conteneur opaque de type lldpctl_atom_t. D’un atome, il est possible
d’extraire des entiers, des chaînes de caractères, des tampons ou
d’autres atomes. La liste des ports est un atome, chaque port de cette
liste est également un atome, la liste des VLAN présents sur ce port
est un atome ainsi que chaque VLAN de cette liste. Le nom d’un VLAN
est par contre une chaîne de caractères dont la validité est limitée
par la validité de l’atome englobant. Accéder à une propriété d’un
atome se fait via des fonctions génériques telles que
lldpctl_atom_get_str() en spécifiant la clé correspondant à la
propriété voulue. Par exemple, voici comment afficher le nom et
l’identifiant de tous les VLAN attachés à un port :
vlans = lldpctl_atom_get(port, lldpctl_k_port_vlans); lldpctl_atom_foreach(vlans, vlan) { vid = lldpctl_atom_get_int(vlan, lldpctl_k_vlan_id)); name = lldpctl_atom_get_str(vlan, lldpctl_k_vlan_name)); if (vid && name) printf("VLAN %d: %s\n", vid, name); } lldpctl_atom_dec_ref(vlans);
En interne, un atome est typé et maintient un compteur des
références. La taille de l’API est limitée grâce à ce
concept. Actuellement, il est possible d’extraire plus d’une centaine
de propriétés de lldpd.
À terme, la bibliothèque doit également permettre la configuration
complète de lldpd plutôt que d’utiliser des paramètres en ligne de
commande. Cette bibliothèque ne remplace pas lldpctl qui est
toujours le client à utiliser dans la majeure partie des cas.
CLI#
La possibilité de configurer lldpd via un fichier de configuration
était demandé depuis bien longtemps. Je ne voulais toutefois pas
inclure un analyseur syntaxique pour limiter l’inflation du nombre de
lignes de code. De plus, il était déjà possible de configurer divers
aspects liés à LLDP-MED via lldpctl. Il m’a donc semblé naturel de
continuer dans cette voie : permettre à lldpctl de lire un fichier
de configuration et d’en transmettre les effets à lldpd. En bonus,
les instructions de configuration pourraient être entrées de manière
interactive à la façon d’un équipement réseau.
Analyse syntaxique & complétion#
Un analyseur syntaxique généré par YACC limite les possibilités telles que la complétion. Aussi, les commandes sont définies par un arbre dont chaque nœud accepte un mot. Un nœud est défini ainsi :
struct cmd_node *commands_new( struct cmd_node *, const char *, const char *, int(*validate)(struct cmd_env*, void *), int(*execute)(struct lldpctl_conn_t*, struct writer*, struct cmd_env*, void *), void *);
On y trouve :
- le nœud parent,
- optionnellement, le mot accepté,
- une description pour l’aide,
- optionnellement, une fonction de validation,
- optionnellement, une fonction qui sera exécutée si le mot est validé.
Le parcours de l’arbre est effectué en maintenant un environnement
contenant à la fois des associations clé-valeur arbitraires ainsi
qu’une pile des positions rencontrées dans l’arbre. La fonction de
validation peut s’aider de l’environnement pour juger de la validité
d’un mot (le mot clé foo ne sera accepté que s’il n’a pas déjà été
rencontré, par exemple). La fonction d’exécution peut enregistrer la
valeur courante dans une association mais également remonter dans
l’arbre avant de continuer l’exécution.
À titre d’exemple, voici comment les nœuds permettant de configurer la localisation par coordonnées géographiques sont définis :
/* Le nœud principal */ struct cmd_node *configure_medloc_coord = commands_new( configure_medlocation, "coordinate", "MED location coordinate configuration", NULL, NULL, NULL); /* Le nœud de sortie La fonction de validation vérifie si l'utilisateur a fourni latitude et longitude. */ commands_new(configure_medloc_coord, NEWLINE, "Configure MED location coordinates", cmd_check_env, cmd_medlocation_coordinate, "latitude,longitude"); /* Stockage de la valeur de la latitude. On remonte ensuite de deux positions en arrière. La latitude ne peut être entrée qu'une fois. */ commands_new( commands_new( configure_medloc_coord, "latitude", "Specify latitude", cmd_check_no_env, NULL, "latitude"), NULL, "Latitude as xx.yyyyN or xx.yyyyS", NULL, cmd_store_env_value_and_pop2, "latitude"); /* De même pour la longitude */ commands_new( commands_new( configure_medloc_coord, "longitude", "Specify longitude", cmd_check_no_env, NULL, "longitude"), NULL, "Longitude as xx.yyyyE or xx.yyyyW", NULL, cmd_store_env_value_and_pop2, "longitude");
Les définitions sont encore un peu verbeuses mais ce système semble être un bon équilibre entre puissance et simplicité. Il couvre tous les cas nécessaires.
Readline#
Face à une interface en ligne de commande, l’utilisateur s’attend généralement à disposer d’un historique, d’une aide en ligne et de la complétion. La bibliothèque la plus souvent utilisée pour cet usage est la bibliothèque GNU Readline. Toutefois, en raison de sa licence (GPL), j’ai d’abord cherché une alternative. Il en existe de nombreuses :
- NetBSD Editline library (
libedit). - Autotool port of the NetBSD Editline library (encore
libedit). - Debian version of the Editline library (
libeditline). - linenoise, une bibliothèque minimalistique.
- Beaucoup d’autres.
Les trois premières bibliothèques supportent la même API que GNU Readline. Elles disposent en sus d’une API commune native. Cette dernière gère également l’analyse lexicale. J’ai donc en premier lieu adopté cette API3.
Malheureusement, j’ai remarqué par la suite que ces bibliothèques ne sont pas beaucoup répandues dans le monde Linux. En utilisant l’API native, il n’est pas possible de se rabattre sur la GNU Readline. J’ai donc changé mon fusil d’épaule et opté pour l’API de la GNU Readline. Une macro issue de l’archive Autoconf (légèrement modifiée) règle les disparités en ce qui concerne la compilation et la liaison.
L’absence d’analyseur lexical intégré m’a obligé à écrire le mien. L’API est également assez mal documentée et il est difficile de savoir quels symboles sont disponibles dans quelle version. Je me suis limité aux symboles suivants :
readline(),addhistory();rl_insert_text();rl_forced_update_display();rl_bind_key();rl_line_bufferetrl_point.
Malheureusement, les implémentations de libedit ne gèrent pas
correctement rl_bind_key(). Aussi, la complétion et l’aide en ligne
ne sont pas disponibles avec celle-ci. La plupart des BSD viennent
avec la GNU Readline préinstallée (elle bénéficie alors de
l’exception liée aux bibliothèques systèmes). Pour le reste, il est
toujours possible de se lier avec libedit et éviter ainsi les
problèmes de licence. Dans ce cas, l’aide peut être obtenue avec la
commande help.
Changements spécifiques à un OS#
Netlink sous Linux#
Précédemment, la liste des interfaces était récupérée via
getifaddrs(). lldpd utilise désormais directement Netlink sur
Linux. Ce n’est pas un changement majeur car la bibliothèque C
utilisait déjà Netlink à cet effet. Les informations supplémentaires
que l’on peut obtenir par ce biais ne sont pour le moment pas
exploitées : elles sont toujours récupérées via sysfs ou
ioctl(). Toutefois, lldpd est notifié lors du moindre changement.
Comme beaucoup d’autres projets, j’ai réécrit ma propre implémentation de Netlink au lieu d’utiliser des bibliothèques telles que libnl qui incluent tout le nécessaire et bien plus encore. Pourquoi ?
-
La dernière version de libnl est très jeune et n’est pas disponible dans de nombreuses distributions, dont par exemple Debian Squeeze. Comme pour libevent, il aurait été possible de contourner la difficulté en incluant cette bibliothèque dans lldpd et en l’utilisant lorsqu’il n’y a pas d’alternative dans le système. Mais…
-
La licence de libnl est la LGPL 2.1. La liaison statique est alors un exercice périlleux. Il n’est pas clair si le résultat est une œuvre dérivée ou non. L’interprétation la plus courante est que la liaison statique est autorisée suivant les mêmes termes que dans la LGPL 3. C’est un problème pour de nombreux projets. Par exemple, OGRE a ajouté une exception pour autoriser la liaison statique dans sa version 1.6 puis s’est tourné vers la licence MIT dans sa version 1.7.
J’ai eu une courte discussion avec Thomas Graf à propos de ce problème et il semble disposé à ajouter une telle exception. Cela risque de prendre un peu de temps mais une fois le changement réalisé, j’utiliserai alors la libnl et en profiterai pour mieux exploiter Netlink4.
Support des BSD#
La version 0.5.7 de lldpd ne supportait que Linux. La réécriture utilisant Netlink a été l’occasion d’abstraire correctement le traitement des interfaces et de porter le tout sous les différents BSD. Le premier port a eu lieu pour Debian GNU/kFreeBSD, puis pour FreeBSD, OpenBSD et NetBSD. La structure est la même pour les trois BSD :
getifaddrs()pour obtenir la liste des interfaces,bpf(4)pour s’attacher à une interface et envoyer et recevoir des paquets,PF_ROUTEpour être notifié lors d’un changement.
Chaque BSD utilise ses propres ioctl() pour récupérer les
informations liées aux VLAN, aux ponts et aux agrégats mais ils sont
souvent assez similaires. Le code est généralement repris de
ifconfig.c.
Les ports pour les BSD ont les mêmes fonctionnalités que le port pour Linux, à l’exception de NetBSD qui ne dispose pas du support pour l’inventaire LLDP-MED car je n’ai pas su comment récupérer ces informations.
Le port d’OpenBSD offre de plus une plus grande sécurité en filtrant les paquets envoyés et en interdisant le processus non privilégié de retirer le filtre mis en place :
/* Install write filter (optional) */ if (ioctl(fd, BIOCSETWF, (caddr_t)&fprog) < 0) { rc = errno; log_info("privsep", "unable to setup write BPF filter for %s", name); goto end; } /* Lock interface */ if (ioctl(fd, BIOCLOCK, (caddr_t)&enable) < 0) { rc = errno; log_info("privsep", "unable to lock BPF interface %s", name); goto end; }
C’est une fonctionnalité très appréciable. lldpd est découpé en deux
processus. Un processus privilégié s’attache au port et transmet
celui-ci à un processus non privilégié. Sans cette fonctionnalité, le
second processus peut simplement retirer le filtre BPF. J’ai porté la
possibilité d’interdire le retrait d’un filtre
sous Linux. Toutefois, il me reste toujours à écrire le nécessaire
pour le filtre des paquets sortants.
Support de macOS#
Une fois le support pour FreeBSD fonctionnel, celui de macOS fut assez simple. J’ai obtenu de xcloud.me une machine virtuelle sous macOS pour m’aider dans cette tâche. Le port n’a ensuite pris que deux jours dont une partie du temps à chercher comment ne pas fournir un numéro de carte de crédit à Apple pour pouvoir télécharger Xcode !
Afin de faciliter l’installation de lldpd, j’ai également écrit une formule pour Homebrew qui semble le gestionnaire de paquets le plus populaire actuellement pour macOS.
Support de Upstart et systemd#
De nombreuses distributions proposent désormais Upstart ou
systemd en remplacement ou en alternative au système d’init
historique. Comme de nombreux démons, lldpd se détache du terminal
et tourne en tâche de fond en forkant deux fois lorsqu’il est prêt
(pour lldpd, cela signifie simplement que la socket Unix a été mise
en place). Bien qu’il soit possible de garder ce comportement avec
Upstart et systemd, il est préférable de ne plus forker. Comment
indiquer alors que le démon est prêt à remplir sa tâche ?
Avec Upstart, lldpd s’envoie le signal SIGSTOP. Upstart va
détecter son état et lui envoyer le signal SIGCONT. De plus, il va
considérer que le démon est prêt. Voici comment faire :
const char *upstartjob = getenv("UPSTART_JOB"); if (!(upstartjob && !strcmp(upstartjob, "lldpd"))) return 0; log_debug("main", "running with upstart, don't fork but stop"); raise(SIGSTOP);
La configuration de Upstart ressemble à ceci :
# lldpd - LLDP daemon description "LLDP daemon" start on net-device-up IFACE=lo stop on runlevel [06] expect stop respawn script . /etc/default/lldpd exec lldpd $DAEMON_ARGS end script
Mise à jour (05.2019)
Les versions actuelles n’utilisent plus ce système de signalisation en raison d’un bug dans Upstart.
systemd emploie une socket sur laquelle le démon envoie la chaîne
READY=1 quand il est prêt. En utilisant la bibliothèque destinée à
cet effet, il suffit d’appeler sd_notify("READY=1\n"). La fonction
sd_notify() pouvant être réécrite en moins de 30 lignes, il m’a
semblé plus simple de le faire plutôt que d’ajouter une dépendance
externe. Voici la configuration de systemd :
[Unit] Description=LLDP daemon Documentation=man:lldpd(8) [Service] Type=notify NotifyAccess=main EnvironmentFile=-/etc/default/lldpd ExecStart=/usr/sbin/lldpd $DAEMON_ARGS Restart=on-failure [Install] WantedBy=multi-user.target
Fichiers d’entête spécifiques à Linux#
Les fichiers d’entête issus du noyau ont toujours été très problématiques. Ils peuvent contenir des erreurs les rendant difficiles à utiliser en espace utilisateur ou être simplement manquants. Il y a longtemps, ils faisaient partie de la bibliothèque C et étaient synchronisés très rarement. Ils ont ensuite été extraits du noyau sans aucun changement et ne correspondaient pas forcément au noyau par défaut de la distribution5.
Il s’agit d’un problème qui tend à disparaître aujourd’hui. D’un côté, les distributions empaquettent désormais les entêtes correspondant au noyau par défaut. De l’autre, les développeurs noyau séparent les entêtes propres au noyau des entêtes destinés à être utilisés par l’espace utilisateur. Toutefois, il faut toujours gérer l’historique.
Un bon exemple est linux/ethtool.h:
- Il peut simplement être absent alors que les fonctionnalités associées sont supportées depuis très longtemps.
- Il peut utiliser les types
u8,u16qui sont spécifiques au noyau. Pour contourner ce problème, il faut altérer les types. - Certaines définitions telles que
SPEED_10000peuvent manquer. Dans ce cas, on peut soit compléter les définitions dans un autre fichier et se retrouver avec une copie du fichier d’entête dans laquelle les définitions sont entrelacées avec des#ifdef, soit n’utiliser les symboles que s’ils sont présents. La dernière solution n’est pas plus pratique et elle interdit d’utiliser des fonctionnalités qui sont pourtant présentes dans le noyau.
Une solution très simple pour résoudre ce problème est simplement d’inclure les fichiers d’entête dans l’arbre de source du projet. Grâce à Google qui a recopié maladroitement ceux-ci pour sa bibliothèque C Bionic, nous savons désormais que la copie des entêtes du noyau dans un programme ne constitue pas une œuvre dérivée.
-
L’utilisation des types
u_int16_tetu_int8_test un reste du système précédent où le sérialiseur devait connaître la taille de chaque membre. ↩︎ -
Pour des conseils plus élaborés, jetez un œil sur Writing a C library. Lisez aussi les conseils de Sean Barret ou ceux de Chris Wellons. ↩︎
-
L’analyse lexicale n’est pas le seul avantage de cette API native. Elle est également beaucoup mieux conçue, ne repose pas sur des variables globales et est bien documentée. Ses implémentations sont de plus sous licence BSD. ↩︎
-
Quelques années plus tard, la situation n’a pas changé : quelques contributeurs sont opposés à l’ajout d’une exception ou à un changement de licence. ↩︎
-
Par exemple, dans Debian Sarge, le noyau était un 2.6.8 (2004) tandis que les entêtes du noyau provenaient d’un noyau antérieur au 2.6. ↩︎