Terminaison TLS : stunnel, nginx & stud
Vincent Bernat
Pour les pressés : les meilleures performances pour une terminaison TLS sont obtenues à l’aide de stud sur un système 64 bits avec le patch d’Émeric Brun pour le cache de sessions en utilisant l’algorithme AES (en 128 bits ou 256 bits, cela n’a pas beaucoup d’importance pour les performances) sur autant de cœurs que possible (performances quasiment linéaires) et avec des clefs de 1024 bits à moins d’avoir réellement besoin de plus.
Mise à jour (10.2011)
Suite à de nombreuses remarques, de nouveaux benchs complémentaires ont été effectués. Après avoir lu cet article, rendez-vous pour le second round.
Mise à jour (02.2015)
Bien que le contenu de cet article soit toujours pertinent, il est important de comprendre qu’il a été rédigé en 2011 et qu’il ne prend pas en compte certains aspects contemporains, notamment la chute de RC4 en tant qu’algorithme approprié.
Mise à jour (01.2016)
stud n’est plus maintenu. Il a été repris par l’équipe de Varnish et s’appelle désormais hitch. Je vous conseille toutefois HAProxy. Il dispose désormais du support de TLS, ajouté par un contributeur majeur de stud.
Introduction#
Il y a un an, Adam Langley, de Google, encourageait l’activation de TLS sur les frontaux web en indiquant que TLS n’était désormais plus coûteux en ressources (traduction libre) :
En janvier de cette année (2010), Gmail a activé le HTTPS par défaut pour tout le monde. Précédemment, il s’agissait d’une option mais désormais, tous nos utilisateurs emploient HTTPS pour sécuriser leurs emails entre leur navigateur et Google, tout le temps. Pour ce faire, nous n’avons pas eu besoin de déployer de nouvelles machines, ni d’employer du matériel dédié. Sur nos frontaux, SSL/TLS représente moins de 1 % de la charge CPU, moins de 10 Kio de la mémoire par connexion et moins de 2 % de la charge réseau. Beaucoup croient que SSL est consommateur en CPU et nous espérons que les chiffres ci-dessus (publics pour la première fois) permettront de chasser cette idée.
Si vous arrêtez de lire ici, ne retenez qu’une seule chose : SSL/TLS n’est désormais plus coûteux en ressources.
Cet article est une lecture très intéressante et présente les points importants à vérifier afin de réduire la latence des connexions TLS. Toutefois, si, contrairement à Gmail, les performances brutes de TLS peuvent être importantes : les frontaux peuvent servir plus de 2000 requêtes par seconde sur un seul CPU ou la terminaison TLS peut avoir lieu sur un répartiteur de charge (même si ce n’est pas la meilleure façon de monter en charge).
Tuning TLS#
Il existe de nombreux facteurs qui peuvent affecter les performances TLS : l’implémentation choisie, le nombre de cœurs à l’œuvre, être ou non en 64 bits, la suite d’algorithmes choisie par les deux parties, la taille des clefs et enfin le cache de sessions.
Nous allons tester trois terminaisons TLS. Ils utilisent tous les
trois OpenSSL. stunnel est le plus ancien et utilise
des threads pour gérer plusieurs clients. stud est une
tentative récente pour écrire une terminaison TLS qui soit simple et
très efficace. Il utilise le modèle « un processus par
cœur ». nginx est un serveur web qui peut également faire
office de reverse proxy. Il est donc également capable de faire
office de terminaison TLS. Il a la réputation d’être un serveur web très
efficace d’où le choix pour ce comparatif. Il est également capable de
faire de la répartition de charge très simple. Ni stud, ni stunnel1
n’étant dotés d’une telle fonctionnalité, nous les couplons avec
HAProxy, un répartiteur de charge haute performance qui
confie habituellement la tâche de terminaison TLS à stunnel mais
stud sait aussi s’y interfacer.
Ces trois implémentations ont été testées récemment par Matt Stancliff. Il a d’abord conclu que nginx était très mauvais en TLS puis que nginx n’était pas très mauvais en TLS (dans le premier cas, nginx était le seul à sélectionner une suite d’algorithmes faisant appel à DHE). Il y a malheureusement très peu de détails dans ces deux articles et j’espère en fournir davantage ici.
Cela nous conduit à parler de l’importance de la suite d’algorithmes négociée entre le client et le serveur pour le chiffrement symétrique. Le serveur sélectionne la suite la plus sûre (à son sens) parmi les suites proposées par le client. Si une suite particulièrement coûteuse est activée côté serveur, il est probable qu’elle soit sélectionnée. C’est donc essentiellement côté serveur que la configuration doit être faite.
Le dernier réglage particulièrement important est celui du cache de sessions. Il influe aussi bien les performances que la latence. Durant le premier échange, le serveur va envoyer un identifiant de session. Lors des échanges suivants, le client pourra présenter cet identifiant pour demander à effectuer une poignée de main abrégée (abbreviated handhsake). Celle-ci est plus courte (amélioration de la latence par suppression d’un aller-retour) et autorise à réutiliser le secret principal négocié précédemment (augmentation des performances en sautant l’étape la plus coûteuse). L’article d’Adam Langley contient une session expliquant plus en détail ce mécanisme (avec des dessins).
Le tableau suivant montre quelle est la suite d’algorithmes choisie par quelques gros serveurs web. J’ai également indiqué si ceux-ci supportent correctement la réutilisation des sessions. Cet article de Matt Palmer indique comment vérifier ceci.
| Site | Algorithmes | Réutilisation de session ? |
|---|---|---|
| www.google.com | RC4-SHA | ✓ |
| www.facebook.com | RC4-MD5 | ✓ |
| twitter.com | AES256-SHA | ✕ |
| windowsupdate.microsoft.com | RC4-MD5 | ✕ |
| www.paypal.com | AES256-SHA | ✕ |
| www.cmcicpaiement.fr | DHE-RSA-AES256-SHA | ✓ |
La RFC 5077 propose un autre mécanisme pour reprendre une session précédente sans pour autant devoir garder un état côté serveur. Ce mécanisme est orthogonal à celui que nous venons de décrire. Je l’explique plus en détail dans un article sur comment activer la réutilisation des sessions TLS.
Benchmarks#
Tous les tests ont été effectués sur un HP DL 380 G7 avec deux Xeon
L5630 tournant à 2.13GHz pour un total de huit cœurs, sans
hyperthreading, avec un noyau 2.6.39 (HZ égal à 250) et deux
cartes réseau Intel 82576. Le sous-système de suivi des connexions de
Linux a été désactivé et la limite sur le nombre de fichiers ouverts a
été monté à 100 000.
Un boîtier Spirent Avalanche 2900 est mis en œuvre pour conduire les tests. À noter que c’est lui qui va imposer la suite d’algorithmes à utiliser en n’en proposant qu’une seule côté client.
Nous nous intéressons essentiellement aux performances du point de vue du nombre de sessions par seconde. Comme nous voulons également observer l’effet du cache de sessions, le scénario joué pour chaque client contient quatre requêtes successives pour lesquelles il y aura réutilisation de l’identifiant de session. Il n’y a ni compression, ni utilisation d’un mécanisme de persistence des requêtes HTTP. Les pages servies sont de 1024 octets exactement.
Notons enfin que HAProxy est capable de servir 22 000 requêtes par seconde sur un seul cœur. Durant les tests, il n’a jamais été le facteur limitant.
Choix de l’implémentation#
Le premier test consiste à évaluer les performances comparées de nginx, stud et stunnel sur un seul cœur. Nous faisons tourner ce test sur un système 32 bits en utilisant la suite AES128-SHA1 et une clé de 1024 bits. Voici le résultat obtenu avec stud (en version 0.1 et avec le patch d’Émeric Brun pour le cache de sessions):
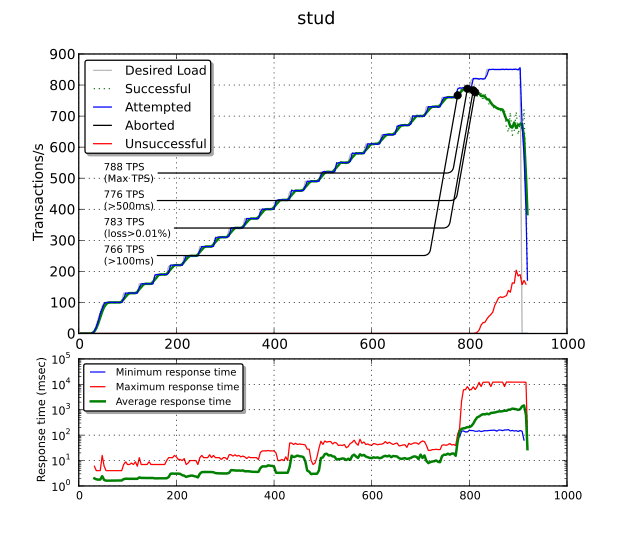
Le graphique du haut est le plus important. La ligne bleue représente le nombre de transactions par seconde (TPS) tentées par l’Avalanche tandis que la ligne verte indique le nombre de TPS qui ont réussies. Quand les deux lignes commencent à diverger, cela indique que nous avons atteint un maximum de ce que peut supporter la solution. La ligne rouge, qui représente le nombre de TPS qui ont échouées, commence alors à monter.
Plusieurs points sont mis en exergue : le nombre maximal de TPS (788 TPS), le nombre maximal de TPS en maintenant un temps de réponse inférieur à 100 ms (766 TPS) puis inférieur à 500 ms (776 TPS) et enfin le nombre maximal de TPS avec un taux d’erreur inférieur à 0,01 % (783 TPS).
Comparativement, voyons les résultats obtenus avec nginx (en version 1.0.5) :
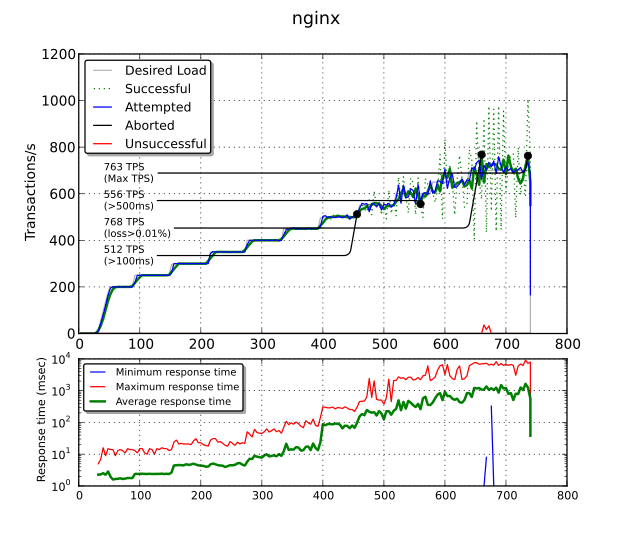
Il obtient des performances brutes très proches de stud (763
TPS). Toutefois, au-delà de 512 TPS, les temps de réponse passent
au-dessus de 100 ms. Pire, au-delà de 556 TPS, nous obtenons plus de
500 ms. Ce comportement est constant dans chaque test (avec ou sans
proxy_buffering, avec ou sans tcp_nopush, avec ou sans
tcp_nodelay) et je suis incapable de l’expliquer. Peut-être y a-t-il
un souci dans la configuration utilisée ? Après avoir
atteint cette limite, nginx traite les connexions par lots. Afin
d’atténuer les pics, le nombre de TPS réussies est tracé en vert
pointillé tandis que la moyenne glissante sur 20 secondes de cette
même mesure est tracée en vert plein.
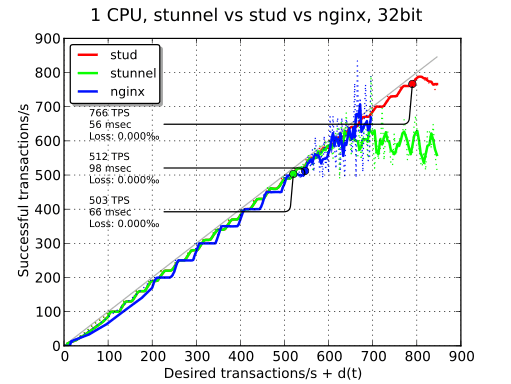
Sur le graphique ci-dessous, les performances des trois implémentations ont été superposées. Pour ce graphique et pour les suivants, la mesure retenue est le nombre maximal de TPS tout en maintenant un temps de réponse moyen inférieur à 100 ms et une perte de paquets inférieure à 0,1 %. stud monte donc à 766 TPS, tandis que nginx et stunnel dépassent à peine 500 TPS.
Nombre de cœurs#
Avec plusieurs cœurs, il est possible d’en dédier aux processus effectuant les calculs TLS. Les différents tests sont joués avec ces répartitions :
| 1 core | 2 cores | 4 cores | 6 cores | |
|---|---|---|---|---|
| CPU 1, Core 1 | network | network | network | network + haproxy |
| CPU 1, Core 2 | haproxy | haproxy | haproxy | TLS |
| CPU 1, Core 3 | TLS | TLS | TLS | TLS |
| CPU 1, Core 4 | - | TLS | TLS | TLS |
| CPU 2, Core 5 | - | - | network | TLS |
| CPU 2, Core 6 | - | - | TLS | TLS |
| CPU 2, Core 7 | - | - | TLS | TLS |
| CPU 2, Core 8 | system | system | system | system + haproxy |
Nous avons deux CPU et quatre cœurs sur chaque CPU. Les cœurs d’un
même CPU se partagent le même cache L2 (sur ce modèle de CPU). Ainsi,
à l’intérieur d’un même CPU, l’ordre a peu d’importance. Si possible,
nous essayons de tout faire à l’intérieur d’un même CPU. Les processus
TLS ont toujours le CPU pour eux seuls puisque ce seront eux qui vont
saturer. La répartition est mise en place avec cpuset(7) en
ce qui concerne les processus et en configurant smp_affinity pour
les interruptions des cartes réseau.
Nous gardons un cœur pour le système. Il est en effet assez important de toujours être capable de se connecter et de surveiller ce dernier, même lors des fortes charges. Avec autant de cœurs, c’est quelque chose que l’on peut se permettre.
Attention ! Il y a un piège quant à l’ordre des cœurs. Il faut lire
attentivement le contenu de /proc/cpuinfo pour déterminer à quel
processeur appartient chaque cœur. Parfois, le second cœur d’un point
de vue du noyau est le second cœur du premier processeur, mais il peut
aussi s’agir du premier cœur du second processeur !
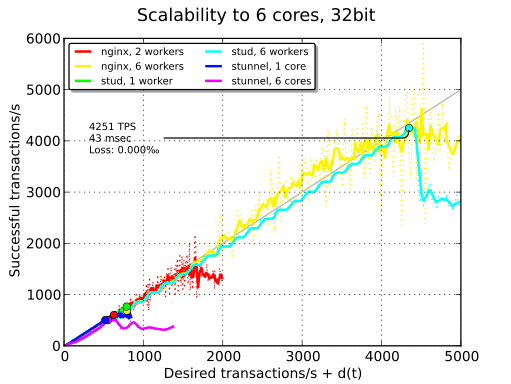
Comme le montre le graphique ci-dessus, seul stud est capable d’utiliser au mieux plusieurs cœurs. stunnel est absolument incapable de monter en charge et produit des performances pires qu’avec un seul cœur. Il est possible que le système de test soit un peu ancien et que l’implémentation des threads ne soit donc pas optimale. nginx suit stud en ce qui concerne les TPS, mais se trouve disqualifié en raison des problèmes de latence. La suite des tests se fait sans stunnel.
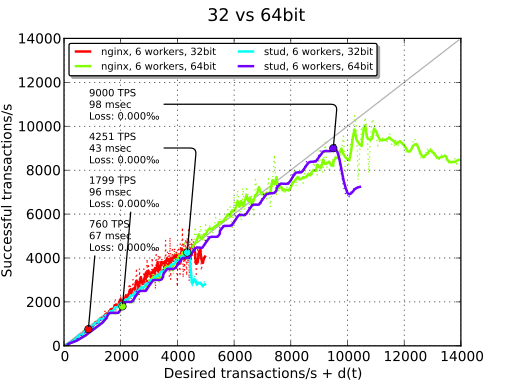
32 vs 64 bits#
La façon la plus simple d’améliorer les performances de manière considérable est de passer de 32 à 64 bits. Les TPS sont alors doublés. Notons également que sur notre système de test, le passage en 64 bits implique également l’utilisation d’AES-NI en raison d’une version d’OpenSSL supportant cette extension. AES-NI est une extension du CPU accélérant le chiffrement et le déchiffrement d’AES. La suite des tests se fait en 64 bits et uniquement avec stud (les défauts de nginx sont toujours présents en 64 bits).
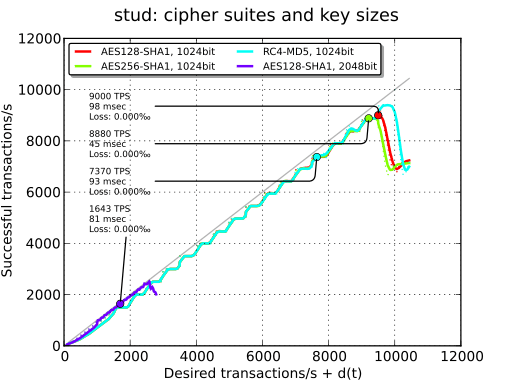
Algorithmes et tailles des clefs#
Dans nos tests, le choix des algorithmes a peu d’influence. Il n’y a que peu de différence entre l’AES 256 et l’AES 128. Utiliser RC4 ajoute légèrement de latence (ce n’est pas le cas en 32 bits) ce qui tend à montrer le bon fonctionnement d’AES-NI.
Par contre, si une clé de 2048 bits est utilisée, les performances sont divisées par 5.
Cache des sessions#
La dernière chose à tester est l’influence du cache de sessions. Comme nous sommes sur un réseau local, la latence est relativement minimale et nous n’allons voir qu’un des points positifs de ce cache : des performances accrues au niveau des TPS en raison de l’usage CPU moindre. L’économie d’un aller-retour ne sera que peu significatif.
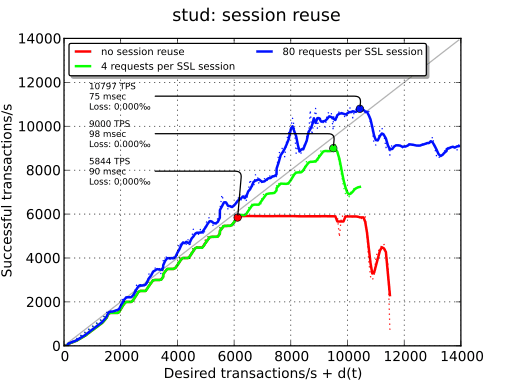
Ce graphique explique de plus pourquoi on observe toujours une baisse des performances avec stud après le point culminant : en raison des sessions qui échouent, le cache est alors moins efficace. Ce phénomène n’existe pas quand il n’y a pas utilisation du cache.
Conclusion#
Le tableau ci-dessous résume les différents chiffres obtenus au cours des tests. Pour rappel, le nombre de TPS retenu est celui pour lequel le temps de réponse moyen est inférieur à 100 ms. Le test témoin est le suivant : 64 bits, 6 cœurs, AES 128, SHA1, clé de 1024 bits, 4 requêtes dans la même session TLS.
| Contexte | nginx 1.0.5 | stunnel 4.41 | stud 0.1 (patched) |
|---|---|---|---|
| 1 cœur, 32 bits | 512 TPS | 503 TPS | 766 TPS |
| 2 cœur, 32 bits | 599 TPS | - | - |
| 32 bits | 804 TPS | 501 TPS | 4251 TPS |
| - | 1799 TPS | - | 9000 TPS |
| AES256 | - | - | 8880 TPS |
| RC4-MD5 | - | - | 7370 TPS |
| 2048-bit | - | - | 1643 TPS |
| pas de réutilisation des sessions | - | - | 5844 TPS |
| 80 requêtes par session TLS | - | - | 10797 TPS |
Ainsi, stud, dans notre scénario témoin, est capable de servir 1500 TPS par cœur. Il semble donc qu’il soit actuellement la meilleure solution pour mettre en place une terminaison TLS. Il n’est pas encore disponible dans Debian, mais j’ai indiqué mon intention de l’empaqueter.
Voici comment stud est lancé :
# ulimit -n 100000
# stud -n 2 -f 172.31.200.15,443 -b 127.0.0.1,80 -c ALL \
> -B 1000 -C 20000 --write-proxy \
> =(cat server1024.crt server1024.key dhe1024)
Jetez également un œil sur la configuration de HAProxy, à celle de nginx et à celle de stunnel.
Mise à jour (10.2011)
Des tests complémentaires ont été effectués. Rendez-vous à la seconde partie.